
Lip sync
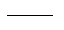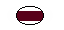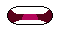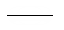
Lip Sync is an application that shows mouth shapes on screen corresponding to real-time speech from a microphone (I recorded the GIF above while speaking "hello" into my microphone).
Motivation
I had been streaming some of my gaming and software development on Twitch. It's common on Twitch for streamers to share their face somewhere in their video feed, but I didn't care to share my real face. I had seen other streamers using some software that allows them to substitute webcam footage with a virtual character. I noticed a few problems with the existing software:
-
The best software produced unnatural mouth movements.
-
The simplest software only provided a binary speaking/silence mode of "lip sync".
-
The best software used a lot of CPU and GPU resources.
I know how to write software, maybe I could do better? Or at the very least learn how one might build such software.
I was also looking to broaden my skillset as a programmer with some low-level programming because I had spent the previous ten years of my career building web applications with JavaScript, Java, C#, and SQL (among many other languages, libraries, frameworks, and platforms).
How it works
graph TB
%% Entities
User
subgraph Client
WebPage[Web Page]
Viseme
SpriteSheet[Sprite Sheet]
EventSource
end
subgraph Server
Microphone
Waveform
Phoneme
WebServer[Web Server]
end
%% Relationships
User -- visits --> WebPage
User -- speaks into --> Microphone
Microphone -- produces --> Waveform
Waveform -- produces (via DSP) --> Phoneme
Phoneme -- stores in --> WebServer
WebServer -- relays phoneme changes to --> EventSource
EventSource -- maps phonemes to --> Viseme
Viseme -- renders to --> WebPage
SpriteSheet -- houses bitmaps for --> Viseme
The application is started on a Windows host with a microphone. The application asks Windows for microphone data at regular, rapid intervals and starts an HTTP server.
As clients connect to the server, they establish a connection with the server, waiting for phoneme data. The client then maps the phoneme to a viseme from a sprite sheet and renders the corresponding sprite.
As microphone data comes in on the server, that data is passed through a chain of transformations (a.k.a. digital signal processing or DSP) that result in a "detected phoneme". The web server broadcasts changes in the currently detected phoneme to all connected clients.
Microphone
Part of the self-imposed challenge of this project was to minimize the libraries used for DSP, which meant that to begin my implementation I needed to learn how to get microphone input.
When I finally produced working code that allowed me to visualize a waveform from my microphone, it was the result of using an LLM to run my queries. I didn't use any code from the LLM, but I learned that WASAPI was the tool for the job and that a small library of win32 bindings, zigwin32, was my connection from Zig.
The process is pretty simple:
-
Ask Windows for the default microphone.
-
Get the format of the sample data produced by the microphone.
-
Start capturing frames with a given buffer size / duration.
-
Receive a buffer of frames representing a window of time.
-
Process the frames.
-
Repeat from step 4.
DSP chain
The DSP chain begins with a raw waveform of frames, which are a collection of samples for a single point in time.
The whole algorithm is built on the observation that phonemes can be detected from distinct frequency profiles. Many frequencies are found outside of natural human speech or are much less important when detecting phonemes, so the mel-scale filter banks aim to greatly simplify the frequency data.
Aside from mixing and calculating MFCC distance, all of the following phases in the DSP chain were discovered by querying a variety of LLMs and researching how each phase works.
Mixing
I'm not sure why my microphone produced stereo frames because its specification says it's a mono microphone and the left and right channels are always equal. For further processing I didn't care to maintain two channels, so the first step in the process was to mix them into a single channel:
fn mixStereoToMono(
comptime size: comptime_int,
stereo_frames: @Vector(size * 2, f32),
) @Vector(size, f32) {
const zero_and_even_nums = comptime std.simd.iota(i32, size) * @as(@Vector(size, i32), @splat(2));
const left_mask = zero_and_even_nums;
const left = @shuffle(f32, stereo_samples, stereo_samples, left_mask);
const right_mask = zero_and_even_nums + @as(@Vector(size, i32), @splat(1));
const right = @shuffle(f32, stereo_samples, stereo_samples, right_mask);
return (left + right) / @as(@Vector(size, f32), @splat(2));
}
The result is a buffer of samples through a window in time, also know as a "waveform".
Frequency Spectrum
The next step was to obtain the frequency spectrum by performing a Fourier transform (FT). The frequency spectrum can be described as a buffer of intensities of constituent waveform frequencies.
I tried to use the LLM to understand what the FT is and how it works, but the resource that helped more than any other was the video produced by 3Blue1Brown: But what is the Fourier Transform? A visual introduction..
Because this program deals with discrete samples, a particular form of FT was used known as the [Descrete Fourier Transform] (DFT). Initially I implemented the "naive" DFT algorithm:

After running some tests I discovered that the naive DFT algorithm was horribly taxing on the CPU and that there exists a much faster algorithm that achieves the same exact result: Cooley-Tukey Fast Fourier Transform Algorithm (FFT).
The exact algorithm is large and complex, so I won't bother putting the code here. If I did then I'd feel the need to explain it, but it probably deserves its own article.
I replaced the body of my DFT function with the FFT algorithm and saw HUGE performance gains. I didn't record the exact difference in performance, but my memory says it was something like 75% or more CPU time saved.
The result is a buffer of real and imaginary coefficients at each frequency from zero hertz up to the buffer size in hertz.
Power Spectrum
This step is simple: combine the real and imaginary frequency spectrum coefficients into a single coefficient by squaring each coefficient then adding together their results:
fn toPowerSpectrum(
comptime size: comptime_int,
real_coefs: @Vector(size, f32),
imag_coefs: @Vector(size, f32),
) @Vector(size, f32) {
return (real_coefs * real_coefs) + (imag_coefs * imag_coefs);
}
The result is a buffer of squared magnitude frequency coefficients, also known as the power spectrum. The basically represents the same data as the frequency spectrum.
MFCCs
The next step transforms the power spectrum such that the resulting data is more representative of human speech. My understanding of this phase in the DSP chain is quite limited, but the following graphic helped me understand the first step which involves applying mel-scale filter banks to the power spectrum. The following image illustrates the filter banks that are applied:
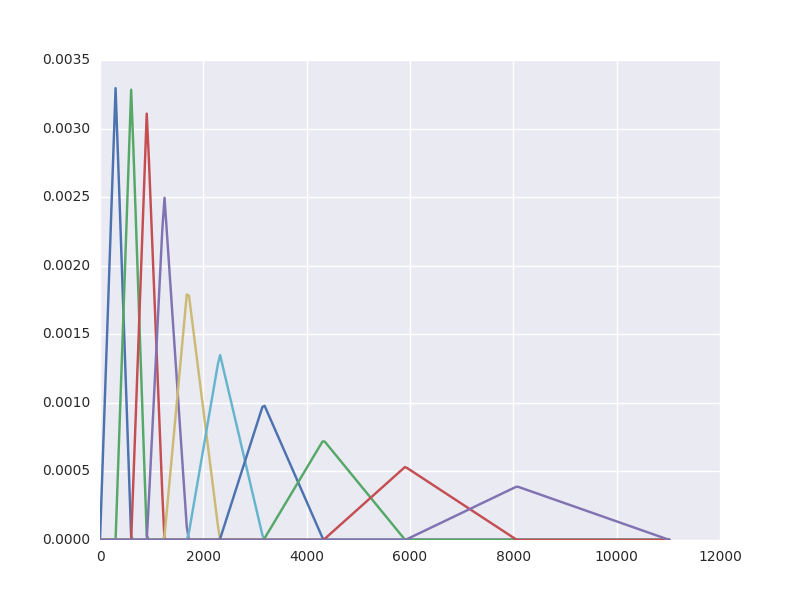
Each triangle represents a mel-scale filter bank, so the resolution of the frequency data from the power spectrum is reduced significantly. The height of the triangle of any given point represents the scale of the frequency data to be summed into that bank.
As seen in the filter bank illustration, the scale of each bank follows a logarithmic curve, so the resulting bank values are then passed through the logarithm function to normalize the values.
Then a [descrete cosine transform] (DCT) is applied to each bank in the mel-scale. I don't understand what this does or how it works, but I understood enough of the math to implement it in Zig.
The result is a sequence of Mel Frequency Cepstrum Coefficients. My research online seems to indicate that nobody quite has a good grasp on what each coefficient represents with relation to the underlying frequency domain or waveform, but apparently it's useful for forming profiles of phonemes.
Phoneme distances
Once I had MFCCs implemented, I recorded and averaged a series of MFCCs for each phoneme I wanted to represent in my final application. I hard-coded the MFCC profiles into my program and called it "training data".
From there I made a function that takes the currently detected MFCCs and compares them against each phoneme's training data to calculate what I'm calling an "MFCC distance": a single number that describes the distance from one MFCC to another. It's probably a little too naive because it just sums the difference of each coefficient.
fn getMfccDistance(expected: []const f32, actual: []const f32) f32 {
var dist: f32 = 0;
// `1..` skips first coefficient because it mostly represents "total energy" instead of anything related to a phoneme profile
for (actual[1..], expected[1..]) |live_coeff, training_coeff| {
dist += @abs(training_coeff - live_coeff);
}
return dist;
}
I then reduce the distances down to a single "phoneme with the shortest MFCC distance" and call that my "detected phoneme".
SIMD
I had been curious about SIMD for a long while now and this felt like a good opportunity to learn about it. Some of the transformations required by this program were well suited to SIMD operations. So I started learning more about SIMD in Zig, which is what those @Vectors and @splats are for.
Web server
Creating a web server from scratch was something I had much less interest in for this particular project (maybe another day). In some past Zig experiments I used Karl Seguin's HTTP server library, httpz. This HTTP server only needed to serve two functions:
-
Serve some static files.
-
Send phonemes to the client in real time.
Real-time server-to-client messaging
I had never used SSE, but I knew from some light reading that SSE was the right tool for the job. The httpz docs that described how to use SSE and it didn't take long to set it up and have live phonemes over the wire.
Client rendering
The static files are simple:
-
HTML file loads everything else.
-
JavaScript connects to server for phonemes.
-
Incoming phonemes are mapped to visemes.
-
Visemes are rendered from a preloaded sprite sheet onto a canvas.
Reflection
My implementation is not nearly as accurate as the existing software I had initially criticized and I think I have a good idea about some areas for experimentation to improve that accuracy. I also learned a lot.
LLM assistant
Before this project I had only ever tried to use LLMs for writing code, but it always felt like wasted effort. This was the first project where it felt like the LLM was being helpful, and its role was basically that of a search engine instead of autocomplete in a code editor.
Naive MFCC distance algorithm
I think the "MFCC distance" idea makes sense, but my particular implementation is perhaps a bit too naive. I say that because some phonemes' training data is already quite close and the calculated distances can sometimes rapidly flip back and forth between two or three phonemes. Some people online seem to have some ideas about better MFCC distance algorithms, but I don't yet know enough to pick any one over another.
Naive training data
My training data is literally a few MFCC snapshots averaged. I haven't been able to find any good information online about better ways to store this kind of training data because I always get results that suggest something like "just use deep learning", but those are the types of solutions I've been trying to avoid due to their performance/latency costs. I have some ideas about how to improve this, for example maybe I could provide ranges and weights for each coefficient of any given phoneme.
Background noise
When my microphone picks up background sounds like heavy breathing, my keyboard, moving in my chair, or the sound of a notification on my phone; it produces phonemes. I'm guessing it wouldn't be very expensive to add a simple noise reduction filter into the chain, though I'd probably also get more benefit out of something more complex that can distinguish human speech from other sounds.
Limited hardware support
I came across a few parts of the program where alternate hardware would behave differently, but I programmed it to get everything running on my own hardware/OS. For example: I mix from stereo to mono using 32-bit floats; if I install a new mic it could use a single channel of 16-bit signed integers instead.
Conclusion
I set out to possibly create a better subset of existing products, found out it was extremely difficult, and learned a lot. I'm more comfortable with Zig and I finally have experience with SIMD, WASAPI, and SSE.
I've decided that I don't want to create an alternative to these programs because I'm satisfied with the things that I learned along the way. Although I have ideas to improve my own software, I think I'm ready to move onto another project.
I'll call this one complete.